728x90
요약
1. TODO 관리 vscode extension Todo Tree
2. 이용해서 문서화 하기
서론
작업을 하다가 당장에 작업을 더 진행할 수 없거나, 어쩔수 없는 사정으로 임시 조치를 하고 넘어가야할 상황이 있다.
우리는 이럴때 // TODO ::: api 연동하기 와 같이 주석을 남겨서 나중에 처리할 일에 넣어둔다.
그리고 나서 코드 검색에서 TODO 텍스트를 검색해서 있는지 없는지를 확인할 수 있겠지만, TODO 리스트 내역들을 따로 볼 수는 없다. 이에 vscode extension 을 이용해서 TODO를 관리해보려고 한다. 물론 Cursor에서도 동일하게 사용 가능하다.
설치
extension 쪽에서 Todo Tree 를 검색하고 설치해준다.
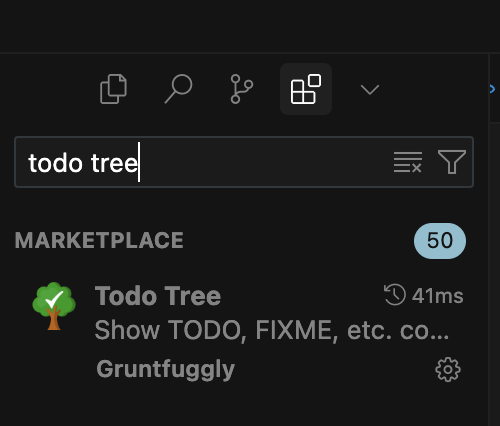
적용 확인

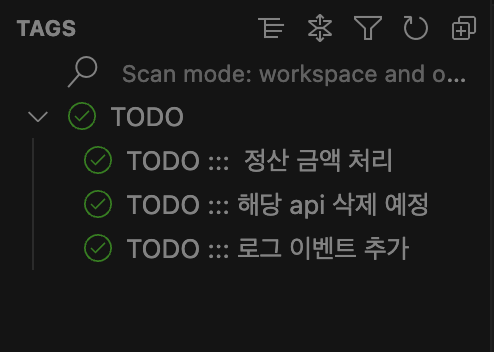
화살표를 클릭해서 TODOs 를 클릭해주면 현재 프로젝트에 작성되어있는 TODO를 정렬해준다.
추가 적으로 햄버거 버튼을 클릭해서 보기 설정을 바꿔주면 더 깔끔하게 TODO 내역들을 확인할 수 있다.

문서화
회사 업무를 하다보면 TODO 내역들을 관리해야할 필요성이 있다. 위에 내용들을 일일이 타이핑해서 작성하는 것은 하수들.
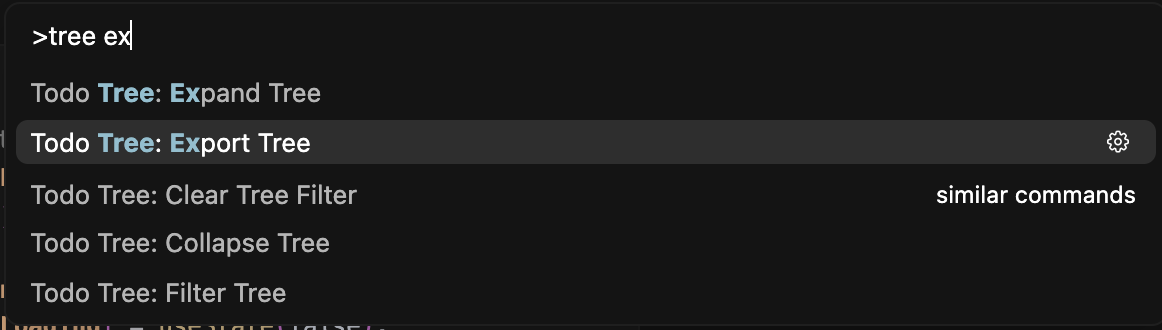
프로출신들은 한번에 문서화를 끝내버린다. command + shift + p 를 눌러서 Todo Tree: Export Tree 를 클릭하면 깔끔하게 TODO 리스트를 텍스트화 시켜준다.

오늘도 최고의 프러덕트를 위해.
728x90
'개발 지식' 카테고리의 다른 글
| [nvmrc] nvm use 자동 적용시키기 (feat. zshrc) (0) | 2025.03.14 |
|---|---|
| [리눅스] bin 폴더가 뭐야? (feat. /bin, /usr/bin, /usr/local/bin) (1) | 2025.03.05 |
| [Turbo] x Found `pipeline` field instead of `tasks` 해결하기 (0) | 2025.02.04 |
| [Git] fatal: The current branch feature/order-agent has no upstream branch.. 해결해보기 (0) | 2024.09.11 |
| [명령 프롬프트] 윈도우 명령프롬프트에서 ls 사용하기 (0) | 2024.08.19 |